 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesinging voice conversion
Papers and Code
OneVoice: One Model, Triple Scenarios-Towards Unified Zero-shot Voice Conversion
Jan 26, 2026Recent progress of voice conversion~(VC) has achieved a new milestone in speaker cloning and linguistic preservation. But the field remains fragmented, relying on specialized models for linguistic-preserving, expressive, and singing scenarios. We propose OneVoice, a unified zero-shot framework capable of handling all three scenarios within a single model. OneVoice is built upon a continuous language model trained with VAE-free next-patch diffusion, ensuring high fidelity and efficient sequence modeling. Its core design for unification lies in a Mixture-of-Experts (MoE) designed to explicitly model shared conversion knowledge and scenario-specific expressivity. Expert selection is coordinated by a dual-path routing mechanism, including shared expert isolation and scenario-aware domain expert assignment with global-local cues. For precise conditioning, scenario-specific prosodic features are fused into each layer via a gated mechanism, allowing adaptive usage of prosody information. Furthermore, to enable the core idea and alleviate the imbalanced issue (abundant speech vs. scarce singing), we adopt a two-stage progressive training that includes foundational pre-training and scenario enhancement with LoRA-based domain experts. Experiments show that OneVoice matches or surpasses specialized models across all three scenarios, while verifying flexible control over scenarios and offering a fast decoding version as few as 2 steps. Code and model will be released soon.
S$^2$Voice: Style-Aware Autoregressive Modeling with Enhanced Conditioning for Singing Style Conversion
Jan 20, 2026We present S$^2$Voice, the winning system of the Singing Voice Conversion Challenge (SVCC) 2025 for both the in-domain and zero-shot singing style conversion tracks. Built on the strong two-stage Vevo baseline, S$^2$Voice advances style control and robustness through several contributions. First, we integrate style embeddings into the autoregressive large language model (AR LLM) via a FiLM-style layer-norm conditioning and a style-aware cross-attention for enhanced fine-grained style modeling. Second, we introduce a global speaker embedding into the flow-matching transformer to improve timbre similarity. Third, we curate a large, high-quality singing corpus via an automated pipeline for web harvesting, vocal separation, and transcript refinement. Finally, we employ a multi-stage training strategy combining supervised fine-tuning (SFT) and direct preference optimization (DPO). Subjective listening tests confirm our system's superior performance: leading in style similarity and singer similarity for Task 1, and across naturalness, style similarity, and singer similarity for Task 2. Ablation studies demonstrate the effectiveness of our contributions in enhancing style fidelity, timbre preservation, and generalization. Audio samples are available~\footnote{https://honee-w.github.io/SVC-Challenge-Demo/}.
HQ-SVC: Towards High-Quality Zero-Shot Singing Voice Conversion in Low-Resource Scenarios
Nov 15, 2025Zero-shot singing voice conversion (SVC) transforms a source singer's timbre to an unseen target speaker's voice while preserving melodic content without fine-tuning. Existing methods model speaker timbre and vocal content separately, losing essential acoustic information that degrades output quality while requiring significant computational resources. To overcome these limitations, we propose HQ-SVC, an efficient framework for high-quality zero-shot SVC. HQ-SVC first extracts jointly content and speaker features using a decoupled codec. It then enhances fidelity through pitch and volume modeling, preserving critical acoustic information typically lost in separate modeling approaches, and progressively refines outputs via differentiable signal processing and diffusion techniques. Evaluations confirm HQ-SVC significantly outperforms state-of-the-art zero-shot SVC methods in conversion quality and efficiency. Beyond voice conversion, HQ-SVC achieves superior voice naturalness compared to specialized audio super-resolution methods while natively supporting voice super-resolution tasks.
R2-SVC: Towards Real-World Robust and Expressive Zero-shot Singing Voice Conversion
Oct 23, 2025In real-world singing voice conversion (SVC) applications, environmental noise and the demand for expressive output pose significant challenges. Conventional methods, however, are typically designed without accounting for real deployment scenarios, as both training and inference usually rely on clean data. This mismatch hinders practical use, given the inevitable presence of diverse noise sources and artifacts from music separation. To tackle these issues, we propose R2-SVC, a robust and expressive SVC framework. First, we introduce simulation-based robustness enhancement through random fundamental frequency ($F_0$) perturbations and music separation artifact simulations (e.g., reverberation, echo), substantially improving performance under noisy conditions. Second, we enrich speaker representation using domain-specific singing data: alongside clean vocals, we incorporate DNSMOS-filtered separated vocals and public singing corpora, enabling the model to preserve speaker timbre while capturing singing style nuances. Third, we integrate the Neural Source-Filter (NSF) model to explicitly represent harmonic and noise components, enhancing the naturalness and controllability of converted singing. R2-SVC achieves state-of-the-art results on multiple SVC benchmarks under both clean and noisy conditions.
The Singing Voice Conversion Challenge 2025: From Singer Identity Conversion To Singing Style Conversion
Sep 19, 2025We present the findings of the latest iteration of the Singing Voice Conversion Challenge, a scientific event aiming to compare and understand different voice conversion systems in a controlled environment. Compared to previous iterations which solely focused on converting the singer identity, this year we also focused on converting the singing style of the singer. To create a controlled environment and thorough evaluations, we developed a new challenge database, introduced two tasks, open-sourced baselines, and conducted large-scale crowd-sourced listening tests and objective evaluations. The challenge was ran for two months and in total we evaluated 26 different systems. The results of the large-scale crowd-sourced listening test showed that top systems had comparable singer identity scores to ground truth samples. However, modeling the singing style and consequently achieving high naturalness still remains a challenge in this task, primarily due to the difficulty in modeling dynamic information in breathy, glissando, and vibrato singing styles.
FCPE: A Fast Context-based Pitch Estimation Model
Sep 18, 2025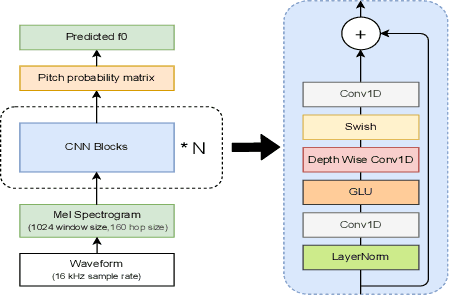
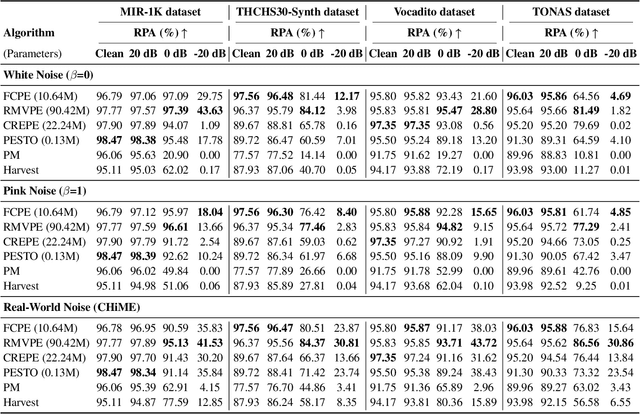
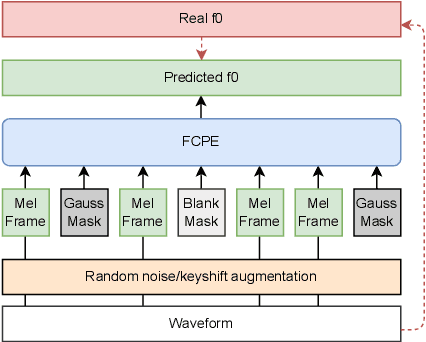

Pitch estimation (PE) in monophonic audio is crucial for MIDI transcription and singing voice conversion (SVC), but existing methods suffer significant performance degradation under noise. In this paper, we propose FCPE, a fast context-based pitch estimation model that employs a Lynx-Net architecture with depth-wise separable convolutions to effectively capture mel spectrogram features while maintaining low computational cost and robust noise tolerance. Experiments show that our method achieves 96.79\% Raw Pitch Accuracy (RPA) on the MIR-1K dataset, on par with the state-of-the-art methods. The Real-Time Factor (RTF) is 0.0062 on a single RTX 4090 GPU, which significantly outperforms existing algorithms in efficiency. Code is available at https://github.com/CNChTu/FCPE.
REF-VC: Robust, Expressive and Fast Zero-Shot Voice Conversion with Diffusion Transformers
Aug 07, 2025In real-world voice conversion applications, environmental noise in source speech and user demands for expressive output pose critical challenges. Traditional ASR-based methods ensure noise robustness but suppress prosody, while SSL-based models improve expressiveness but suffer from timbre leakage and noise sensitivity. This paper proposes REF-VC, a noise-robust expressive voice conversion system. Key innovations include: (1) A random erasing strategy to mitigate the information redundancy inherent in SSL feature, enhancing noise robustness and expressiveness; (2) Implicit alignment inspired by E2TTS to suppress non-essential feature reconstruction; (3) Integration of Shortcut Models to accelerate flow matching inference, significantly reducing to 4 steps. Experimental results demonstrate that our model outperforms baselines such as Seed-VC in zero-shot scenarios on the noisy set, while also performing comparably to Seed-VC on the clean set. In addition, REF-VC can be compatible with singing voice conversion within one model.
VibE-SVC: Vibrato Extraction with High-frequency F0 Contour for Singing Voice Conversion
May 27, 2025Controlling singing style is crucial for achieving an expressive and natural singing voice. Among the various style factors, vibrato plays a key role in conveying emotions and enhancing musical depth. However, modeling vibrato remains challenging due to its dynamic nature, making it difficult to control in singing voice conversion. To address this, we propose VibESVC, a controllable singing voice conversion model that explicitly extracts and manipulates vibrato using discrete wavelet transform. Unlike previous methods that model vibrato implicitly, our approach decomposes the F0 contour into frequency components, enabling precise transfer. This allows vibrato control for enhanced flexibility. Experimental results show that VibE-SVC effectively transforms singing styles while preserving speaker similarity. Both subjective and objective evaluations confirm high-quality conversion.
SingNet: Towards a Large-Scale, Diverse, and In-the-Wild Singing Voice Dataset
May 14, 2025The lack of a publicly-available large-scale and diverse dataset has long been a significant bottleneck for singing voice applications like Singing Voice Synthesis (SVS) and Singing Voice Conversion (SVC). To tackle this problem, we present SingNet, an extensive, diverse, and in-the-wild singing voice dataset. Specifically, we propose a data processing pipeline to extract ready-to-use training data from sample packs and songs on the internet, forming 3000 hours of singing voices in various languages and styles. Furthermore, to facilitate the use and demonstrate the effectiveness of SingNet, we pre-train and open-source various state-of-the-art (SOTA) models on Wav2vec2, BigVGAN, and NSF-HiFiGAN based on our collected singing voice data. We also conduct benchmark experiments on Automatic Lyric Transcription (ALT), Neural Vocoder, and Singing Voice Conversion (SVC). Audio demos are available at: https://singnet-dataset.github.io/.
kNN-SVC: Robust Zero-Shot Singing Voice Conversion with Additive Synthesis and Concatenation Smoothness Optimization
Apr 08, 2025



Robustness is critical in zero-shot singing voice conversion (SVC). This paper introduces two novel methods to strengthen the robustness of the kNN-VC framework for SVC. First, kNN-VC's core representation, WavLM, lacks harmonic emphasis, resulting in dull sounds and ringing artifacts. To address this, we leverage the bijection between WavLM, pitch contours, and spectrograms to perform additive synthesis, integrating the resulting waveform into the model to mitigate these issues. Second, kNN-VC overlooks concatenative smoothness, a key perceptual factor in SVC. To enhance smoothness, we propose a new distance metric that filters out unsuitable kNN candidates and optimize the summing weights of the candidates during inference. Although our techniques are built on the kNN-VC framework for implementation convenience, they are broadly applicable to general concatenative neural synthesis models. Experimental results validate the effectiveness of these modifications in achieving robust SVC. Demo: http://knnsvc.com Code: https://github.com/SmoothKen/knn-svc